Python
之旅 (五)文
/马儿 (marr@linux.org.tw)本期将介绍几个
Unix/Linux 上常见的延伸应用,诸如 grep、find、regular expression 等,这些模组的实作方式,以 Mandrake Linux 7.2 为例,读者都可以在 /usr/lib/python1.5/ 目录下找到原始码。另外,我们也将接触 Python 物件导向语言里的类别与个体物件,透过一些简单的范例,慢慢走入物件导向程式的核心世界。与字串、档案名称有关的模组
grep
模组Python 的 grep 模组里,同样包含 grep()、egrep()、emgrep()、ggrep() 等不同的 grep 物件方法,为了简便学习,读者先熟悉 grep() 即可。
>>> import grep Œ
>>> grep.grep("lib", "/etc/passwd")
16: gopher:x:13:30:gopher:/usr/lib/gopher-data:
20: htdig:x:101:104::/var/lib/htdig:
23: postgres:x:40:235:PostgreSQL Server:/var/lib/pgsql:/bin/bash
>>> grep.grep("bin", "/etc/passwd", "/etc/group") Ž
/etc/passwd: 1: root:x:0:0:root:/root:/bin/bash
/etc/passwd: 2: bin:x:1:1:bin:/bin:
/etc/passwd: 3: daemon:x:2:2:daemon:/sbin:
/etc/passwd: 6: sync:x:5:0:sync:/sbin:/bin/sync
/etc/passwd: 7: shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
/etc/passwd: 8: halt:x:7:0:halt:/sbin:/sbin/halt
/etc/passwd: 23: postgres:x:40:235:PostgreSQL Server:/var/lib/pgsql:/bin/bash
/etc/group: 2: bin:x:1:root,bin,daemon
/etc/group: 3: daemon:x:2:root,bin,daemon
/etc/group: 4: sys:x:3:root,bin,adm
>>>
Œ
使用时请载入 grep 模组。
由上述范例,可以得知模组 grep 里的 grep() 物件方法,其工作方式和 Unix/Linux 上的grep 指令一致,将一个字串当作搜寻值,再接所要进行搜寻的档案名称。其传回值会包括所找到的行内容,并在行内容前标明其所在行数。Ž
值得注意的是,所接档案名称可以超过一个以上,如上例以档案名称字串接续输入,其不同档案内所搜寻到的内容,会在输出结果前,标明其档案名称以作区别。glob
模组如果我们想要使用类似
"*.txt" 这样的档案名称描述方式,可以藉助于 glob 模组的服务,这在之前的档案系统服务说明部份,已是简单介绍过,在此我们再温故知新一番。若忘了先 import glob 模组的话,很可能会回报错误讯息,请参考下列范例。>>> import grep
>>> grep.grep("John", "*.txt")
Traceback (innermost last):
File "<stdin>", line 1, in ?
File "/usr/lib/python1.5/grep.py", line 12, in grep
return ggrep(RE_SYNTAX_GREP, pat, files)
File "/usr/lib/python1.5/grep.py", line 31, in ggrep
fp = open(filename, 'r')
IOError: [Errno 2] No such file or directory: '*.txt'
>>> import glob
>>> grep.grep("John", glob.glob("*.txt"))
beatles.txt: 1: John Lennon
smiths.txt: 2: Johnny Marr
>>> glob.glob('[0-9].*')
['1.gif', '2.txt']
>>> glob.glob('*.gif')
['1.gif', 'card.gif']
>>> glob.glob('?.gif')
['1.gif']
>>>
不过,要分清楚的是,
glob 模组用于档案名称的解析,其解析规则通常与 Unix/Linux shell 的档名解析规则相同,因为 glob 模组的实作方式,使用了 fnmatch 模组。而正规表示式则是使用于字串的解析,通常与档名解析的规则不完全相同。find
模组Python 里的 find 模组,其所提供的功能并不如 Unix/Linux 环境下的 find 程式一般丰富,而且实作方式有其特别之处。
>>> import find
>>> find.find("*") Œ
['./.dot_file.txt', './1.gif', './2.txt', './beatles.txt', './card.gif', './smiths.txt']
>>> find.find("*.txt")
['./.dot_file.txt', './2.txt', './beatles.txt', './smiths.txt']
>>> find.find("*.txt", "..")
['../bob_dylan.txt', '../british/.dot_file.txt', '../british/2.txt', '../british/beatles.txt', '../british/smiths.txt']
>>>
Œ
find() 物件方法最简单的范例,便是以 "*" 为输入参数,它会传回现行目录下的所有档案名称。值得注意的是,包括以‘点符号’(.) 为首的档案名称,也会被符合比对。因为其实作方法,是将所有的档案名称最前面加上 ./ (代表 os.curdir),然后再进行比对。
find() 物件方法可以接第二个参数,指定开始搜寻的起始目录,如例中的 "..",代表上一层目录。正规表示式
(regular expression)如果读者之前已有
Unix 的使用经验,很可能已经透过 shell 或 Perl 的学习过程,认识到正规表示式的功能。正规表示式的内容相当庞杂,如果按部就班、从头学习至尾,将近是一本书的份量,在此并不打算将正规表示式的内容悉数介绍,重点在于让读者了解,Python 一般的正规表示式功能,和 Perl 相较并无逊色之处。正规表示式非常实用,系统管理员、资料库管理员、与网页设计员,相信于此感受更深。其主要应用场合包括‘搜寻’‘取代’‘解析’
(复杂之) 文字字串,值得说明的是,之前已介绍过的 string 模组,该模组中也包括字串搜寻 (index、find、count)、取代 (replace)、解析 (split) 等功能,但大抵仅限于基本而简单的部份,诸如单一字串、明确字串、字母大小区分的场合,读者必须适当分辨应用场合,以便采用最佳的解决方案。>>> import string Œ
>>> s = '100 NORTH MAIN ROAD'
>>> string.replace(s, 'ROAD', 'RD.')
'100 NORTH MAIN RD.'
>>> s = '100 NORTH BROAD ROAD' Ž
>>> string.replace(s, 'ROAD', 'RD.') Ž
'100 NORTH BRD. RD.' Ž
>>> s[:-4] + string.replace(s[-4:], 'ROAD', 'RD.')
'100 NORTH BROAD RD.'
>>> import re
>>> re.sub('ROAD$', 'RD.', s) ‘
'100 NORTH BROAD RD.' ‘
>>>
Œ
先试试 string 模组的功能,将其 import 来使用。
string 模组里的 replace() 物件方法,可以接受三个参数,分别是等待处理的字串 s,以及取代前的字串 'ROAD' 和取代后的字串 'RD.',目的是让 'ROAD' 以缩写字 'RD.' 来取代。Ž
之前的范例很顺利地达到需求,但此例可就把事情搞砸了,照本宣科的话,会把原本不该取代的 BROAD 也换掉。
直觉的变通方法,可以将字串 s 先分成两段处理,由于 'ROAD' 是 4 个字母长度,而且是位于字串最后面,利用字串分割,将倒数 4 个字母前的字串保留,而最后 4 个字母的字串进行取代动作。
上述的变通方法显然缺乏弹性,比如说,若是遇到 'STREET' 要改成缩写字 'ST.' 时,字串分割的字母数必须改为 6,很容易会让人疲于奔命。比较理想的方式,便是利用正规表示式的功能,在此我们载入 re 模组。‘
re 模组里有个 sub() 物件方法,其接受三个参数,分别是‘想要取代的字串样版’,在此例中为 'ROAD$',而第二个参数是‘取代后的字串’'RD.',最后的参数是字串 s。字串样版 'ROAD$' 表示 'ROAD' 将出现在待搜寻字串的结尾处,此时 'BROAD' 因为不在字串结尾处,所以不会被取代,符合我们的需求。Python 里的正规表示式功能由 re 模组提供,其伴随几个有用的模组方法,配合字串样版来进行搜寻、取代、解析等动作。字串样版 (pattern) 是指一组包含有一般文字以及特殊字元序列的字串,例如 '?(P<int>\d+)\.(\d*)' 就是一个复杂点的字串样版,由于字串样版里经常会包含有星号 (*) 或反斜线 (\) 等特殊符号,因此惯例上,会配合原始字串 (raw string) 表示法来处理它,这点我们在之前也提示过。
常见的正规表示式功能介绍
下列的特殊字元最简单且常用,可以先单独予以记忆,并相互对照其使用意义。
|
特殊字元 |
功能说明 |
|
. |
代表除了换行字元以外的所有字元。 |
|
^ |
代表字串位于开头。 |
|
$ |
代表字串位于结尾。 |
|
* |
代表一组出现一次或多次以上的表示模式。 |
|
+ |
代表一组出现零次或多次以上的表示模式。 |
|
? |
代表一组出现零次或一次的表示模式。 |
下列再整理另一组字串样版表示法范例,易学易懂。
|
字串样版范例 |
功能说明 |
|
hello|Hello |
代表 hello或Hello两个字串均符合条件。 |
|
(h|H)ello |
代表 hello或Hello两个字串均符合条件。 |
|
[hH]ello |
代表 hello或Hello两个字串均符合条件。 |
|
[0-9] |
代表 0至9的数字均符合条件。 |
|
[^0-9] |
代表 0至9数字之外的字元符合条件。 |
另外,用于字串样版中的特殊字元可以在前面加上反斜线,用以代表特殊字元本身,但有些反斜线的特别应用,值得额外注意,将常见者整理如下:
|
字元 |
功能说明 |
|
\ number |
代表除了换行字元以外的所有字元。 |
|
\ d |
代表字串位于开头。 |
|
\ D |
代表字串位于结尾。 |
|
\ s |
代表空格字元,即 r'[ \t\n\r\f\v]'。 |
|
\ S |
代表非空格字元,即 r'[^ \t\n\r\f\v]'。 |
|
\ w |
代表英数字,即 [0-9a-zA-Z]。 |
|
\ W |
代表\ w定义以外的所有字元。 |
example$ cat dirbook.txt
Beatles, Liverpool
Lennon, John Winston: 0800-123456
McCartney, James Paul: 0204-123999
Harrison, George: 0800-999333
Starkey, Richard: 0204-123777
Starr, Ringo: 0204-456777
Smiths, Manchester
Morrissey, Steven Patrick: 0928-987654
Marr, Johnny: 0928-849952
Rourke, Andy: 0938111999
Joyce, Mike: 0936555444
上述是一个记录姓名、电话的档案,我们藉其内容先来练习
re 模组所附简单的物件方法,例如搜寻及取代。>>> import re
>>> s = "Johnny Marr"
>>> re.sub("Marr", "Maher", s)
'Johnny Maher'
>>> t = open("dirbook.txt").read()
>>> pat = re.compile(r'John.*:')
>>> re.findall(pat, t)
['John Winston:', 'Johnny:']>>>
根据上述
dirbook.txt 档案的内容,我们再继续来测试正规表示式的其他功能。其内容格式大致为:Last_Name, First_Name Middle_Name: Phone_Number
观察
Last_Name 的组成,只有英文字母而无数字,可用 [a-zA-Z] 来表示,而完整的 Last_Name 包括一个以上的英文字母,所以用 [a-zA-Z]+ 来表示。Last_Name 后紧跟着一个逗号 (,)。First_Name 部份原则上如法泡制,但 Middle_Name 算是可有可无,因此可用 [a-zA-Z]+( [a-zA-Z]+)? 来表示。之后再紧跟着一个冒号 (:)。
Phone_Number 部份,本范例所呈现者并不算复杂,可分成 4 个数字 (数字可用 \d 表示),紧跟一个可有可无的 - 符号,再接 6 个数字,可以用 \d\d\d\d-?\d\d\d\d\d\d 来表示。
档案中,除了两行 "Beatles, Liverpool" 与 "Smiths, Manchester" 之外,都符合上述的表示式分析。
import re
regexp = re.compile(r"[a-zA-Z]+,"
r" [a-zA-Z]+"
r"( [a-zA-Z]+)?"
r": \d\d\d\d-?\d\d\d\d\d\d")
file = open("dirbook.txt", 'r')
for line in file.readlines():
if regexp.search(line):
print "found"
file.close()
执行上述的程式内容,可以得到
9 个 "found" 字串回应,表示从记录档的内容中,成功解析出 9 个符合正规表示式的字串。实务上,透过正规表示式所解析出来的资料,都会希望额外做些加工,再重新以使用者想要的格式来呈现。有个
?P<name> 的应用技巧,可以帮助我们达到这样的功能,请仔细观察下列的范例:(?P<last>[a-z A-Z]+), (?P<first>[a-zA-Z]+)( (?P<middle>([a-zA-Z]+)))?: (?P<phone> (\d\d\d\d-?\d\d\d\d\d\d)
也就是说,每一组具备意义的正规表示式,我们可以个别赋予其一个‘别名’,如
<last>、<first>、<middle>、<phone> 等。值得注意的是,?P<name> 表示法中的问号 (?),与代表‘可有可无’的特殊字元 ? 符号,两者各自独立运作,并无相关,请不要混淆。认识了上述的‘别名’设定技巧,我们就可以再透过
group() 物件方法来取得符合的字串资料。可参考下面的例子:example$ cat re_group.py
import re
regexp = re.compile(r"(?P<last>[a-zA-Z]+),"
r" (?P<first>[a-zA-Z]+)"
r"( (?P<middle>([a-zA-Z]+)))?"
r": (?P<phone>\d\d\d\d-?\d\d\d\d\d\d)"
)
file = open("dirbook.txt", 'r')
for line in file.readlines():
result = regexp.search(line)
if result == None:
print "Not found."
else:
last_name = result.group('last')
first_name = result.group('first')
middle_name = result.group('middle')
if middle_name == None:
middle_name = ""
phone_no = result.group('phone')
print 'Name: ' + first_name + ' ' \
+ middle_name + ' ' \
+ last_name + '\n' \
+ 'Phone: ' + phone_no
file.close()
执行上述程式,可以得到重新整理过的资料内容。
example$ python re_group.py
Not found.
Name: John Winston Lennon
Phone: 0800-123456
Name: James Paul McCartney
Phone: 0204-123999
Name: George Harrison
Phone: 0800-999333
Name: Richard Starkey
Phone: 0204-123777
Name: Ringo Starr
Phone: 0204-456777
Not found.
Name: Steven Patrick Morrissey
Phone: 0928-987654
Name: Johnny Marr
Phone: 0928-849952
Name: Andy Rourke
Phone: 0938111999
Name: Mike Joyce
Phone: 093655544
类别功能
(class)和
Java 语言一样,Python 是一个物件导向式程式语言,其类别功能及类别体系,是物件导向式语言的重要成份。不过,在此我们很难逐步详述物件导向语言的细节内容,以下的说明或范例,重点不在于概念或基础名词的介绍,而是带出 Python 的语法结构。如何定义一个类别
Python 使用 class 叙述来定义一个类别,而由呼叫某一类别名称 (类似函式的呼叫方式) 而建立的新物件,被称为该类别的一个‘个体’(instance),例如:
class MyClass:
body
instance = MyClass()
惯例上,类别在定义时会以大写字母来表示。而一个
instance 可以内含‘资料结构’或‘资料记录’,感觉上与 C 语言的结构语法很像,但实际用法上不必像 C 语言必须事先将结构完成宣告。我们可以直接观察下列的简单范例:class Circle: Œ
pass Œ
myCircle = Circle()
myCircle.radius = 5 Ž
print 2 * 3.14 * myCircle.radius
Œ
定义一个 Circle 类别,其内容‘空空如也’。
建立一个新个体,名为 myCircle。Ž
设定 myCircle 的 radius 值为 5。其设定方式,是在个体物件名称后加上 . 符号,成为 myCircle.radius 这样的描述方式。个体物件的设定值,可由
__init__ 这个起始函式自动完成,通常 __init__ 又被称为类别的‘建构子’(constructor)。每次有新的个体物件被建立,都会找寻 __init__ 的设定内容,自动完成新个体物件的起始设定值。class Circle: Œ
def __init__(self): Œ
self.radius = 1 Œ
def area(self):
return self.radius * self.radius * 3.14159
myCircle = Circle()
print 2 * 3.14 * myCircle.radius
myCircle.radius = 5 Ž
print 2 * 3.14 * myCircle.radius Ž
print myCircle.area()
Œ
类别 Circle 里有个 __init__() 函式,设定其 radius 值为 1。注意到 self 这个参数,惯例上它就是 __init__() 函式的第一个参数,当 __init__ 起始设定时,self 就会被设定为新建立的个体上。
新个体物件建立后,有自己的个体变数 (instance variables),如 radius 即为一例。Ž
个体变数的值可以重新设定。
可以为个体物件设定物件方法 (method),其方式就像定义函式一般。class Circle:
def __init__(self, r=1):
self.radius = r
def area(self):
return self.radius * self.radius * 3.14159
c = Circle(5)
print c.area()
上述则是另一个改进版本的
Circle 类别内容设定,增加预设变数 r,并指定其预设值为 1。如此一来,我们便可透过 Circle(5) 这样的方式来指定新个体的建立。继承功能
(inheritance)继承功能是物件导向式语言的另一项特性,
Python 的继承功能可由下列范例中观察了解:class Square:
def __init__(self, side=1, x=0, y=0):
self.side = side
self.x = x
self.y = y
class Circle:
def __init__(self, rad=1, x=0, y=0):
self.radius = rad
self.x = x
self.y = y
上述并列的两个类别分别是
Square 与 Circle,注意到它们的设定内容有部份雷同,我们可以利用此特性,为它们建立一个‘母类别’。class Shape:
def __init__(self, x, y):
self.x = x
self.y = y
class Square(Shape):
def __init__(self, side=1, x=0, y=0):
Shape.__init__(self, x, y)
self.side = side
class Circle(Shape):
def __init__(self, rad=1, x=0, y=0):
Shape.__init__(self, x, y)
self.radius = rad
我们定义了一个母类别
Shape,以 class Square(Shape) 或 class Circle(Shape) 宣告方式,即可完成继承母类别的第一步骤。值得注意的是,在 Square 与 Circle 继承 Shape 母类别后,记得要明确地使用 Shape.__init__(self, x, y) 物件方法呼叫,使之生效。物件、类别的内容很重要,而且也很容易混淆,在此我们先简单介绍上述基本的
Python 类别、物件功能设定,读者务必要练习熟悉,奠定好基础。类别库功能
(package)我们之前已介绍过模组
(module),简单地看,模组就是一个 Python 程式码档案,里头包含一些函式与物件功能。而呼叫模组时,就是以程式码档案的档案名称来命名。一旦上述的运作模式熟悉了,则类别库 (package) 便不难理解,因为类别库只是在一个目录之下,将一堆功能相近而能相互引用的程式码档案收集在一起。而呼叫类别库时,则是以其上层目录名称来命名。类别库呈现档案目录架构
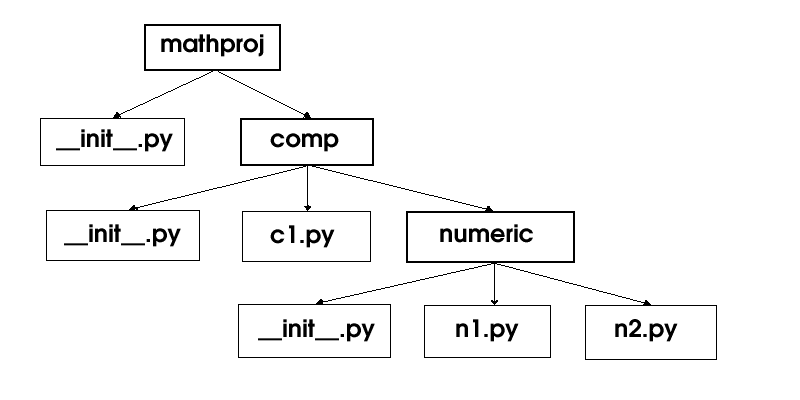
类别库的概念及设计方式,原则上就是模组的扩充,在大型的程式开发专案中,类别库能够整理一组相关的函式、物件、变数,分门别类地安排于目录之下,让程式人员容易进行管理。底下即是一个简略的范例。
图
: 类别库范例示意图中的
mathproj 即代表最上层目录,其底下有一个 __init__.py 档案,以及一个 comp 目录,而 comp 目录下,又类推有 __init__.py 档案、c1.py 档案、numeric 目录,在 numeric 目录下,则有 __init__.py 档案、n1.py 档案、n2.py 档案。__init__.py 档案,其功能也就是类似类别内容设定里的 __init__() 函式,在类别库的设计方式里,以档案型式存在。下列是非常简略的类别库范例的程式内容,用以示范其运作概念。
example$ cat mathproj/__init__.py
print "Hello from mathproj init"
__all__ = ['comp']
version = 1.03
example$ cat mathproj/comp/__init__.py
__all__ = ['c1']
print "Hello from mathproj.comp init"
example$ cat mathproj/comp/c1.py
x = 1.00
example$ cat mathproj/comp/numeric/__init__.py
print "Hello from nemeric init"
example$ cat mathproj/comp/numeric/n1.py
from mathproj import version
from mathproj.comp import c1
from n2 import h
def g():
print "version is", version
print h()
example$ cat mathproj/comp/numeric/n2.py
def h():
print "Called function h in module n2"
执行来测试上述的类别库程式内容时,必须确认
mathproj 目录位于 Python 的搜寻路径中,最简单的方式,便是使用者的现行目录设定在 mathproj 目录之上,然后再开始一个 Python 的对话环境。>>> import mathproj
Hello from mathproj init
>>> mathproj.version
1.03
>>> mathproj.comp.numeric.n1 Œ
Traceback (innermost last):
File "<stdin>", line 1, in ?
AttributeError: comp
>>> import mathproj.comp.numeric.n1
Hello from mathproj.comp init
Hello from nemeric init
>>> mathproj.comp.numeric.n1.g()
version is 1.03
Called function h in module n2
None
Œ
上述的错误讯息,在于 mathproj 载入后,并不代表也自动将 comp、numeric 等子目录里的档案设定都载入,因此使用者必须手动额外载入 mathproj.comp.numeric.n1 才能真正使用到子目录里的设定值。注意到前述
__init__.py 档案程式码里所出现的 __all__ 属性值,我们可以看到其以一个字串串列为设定值,而该字串串列即子目录名称,明确地说,就是用于当 from ... import * 语法出现时,所要载入的目录项目是哪些。由于不同的作业系统,对于档案名称大小写的处理方式不同,以 Unix/Linux 为例,档案名称大小写是视为不同的,而 MS Windows 的环境,则将档案名称大小写视为相同。如此一来,载入档案时便可能造成混淆,而 __all__ 属性值的设定,即是要明确地指定所要载入的目录项目有哪些。如果读者取得
Zope 这套以 Python 所写成的网站应用程式,安装之后便可发现其程式开发,大量应用了类别库功能,有兴趣深入了解类别库设计的读者,可以多多参考 Zope 的 product 内容。相关说明
[1] Regular Expression HOWTO 网页,网址 http://py-howto.sourceforge.net/regex/regex.html
[2] PERL5 Regular Expression Description 网页,网址http://www.cpan.org/doc/FMTEYEWTK/regexps.html
[3] Regular Expression 中文介绍,网址 http://www.cyut.edu.tw/~ckhung/olbook/gnulinux/regexp.shtml
[4] 完整的 Python Regular Expression 语法,网址http://www.python.org/doc/current/lib/module-re.html
[5] Regular Expression Matching 效能比较网页,网址http://www.bagley.org/~doug/shootout/bench/regexmatch/
[6] How to think like a computer scientist -- Python Version 网页,教你如何一窥程式设计的堂奥,网址http://www.ibiblio.org/obp/thinkCSpy/
[7] Python 与其他程式语言之比较,网址http://www.python.org/doc/Comparisons.html
[8] 物件导向式语言之简介,网址 http://catalog.com/softinfo/objects.html
[9] Python Script 能够设计哪些游戏,网址 http://www.digivision.com.tw/DGAdvan/Animation/Ani11/Ani11.htm